Can we use off-the-shelf large pre-trained models (LPMs) as synthetic data generators for effective few-shot dataset augmentation toward specific distributions?
The performance of deep learning models is intrinsically tied to the quality, volume, and relevance of their training data. Gathering ample data for production scenarios often demands significant time and resources. Among various strategies, data augmentation circumvents exhaustive data collection by generating new data points from existing ones. However, traditional augmentation techniques can be less effective amidst a shift in training and testing distributions.
This paper explores the potential of synthetic data by leveraging large pre-trained models for data augmentation,
especially when confronted with distribution shifts.
Although recent advancements in generative models have enabled several prior works in cross-distribution data generation,
they require model fine-tuning and a complex setup. To bypass these shortcomings,
we introduce Domain Gap Embeddings,
a plug-and-play semantic data augmentation framework in a cross-distribution few-shot setting.
Our method extracts disparities between source and desired data distributions in a latent form,
and subsequently steers a generative process to supplement the training set with endless diverse synthetic samples.
Our evaluations, conducted on a subpopulation shift and three domain adaptation scenarios under a few-shot paradigm,
reveal that our versatile method improves performance across tasks without needing hands-on intervention or intricate fine-tuning.
Our method paves the way to effortlessly generate realistic, controllable synthetic datasets following the test distributions,
bolstering real-world efficacy for downstream task models.
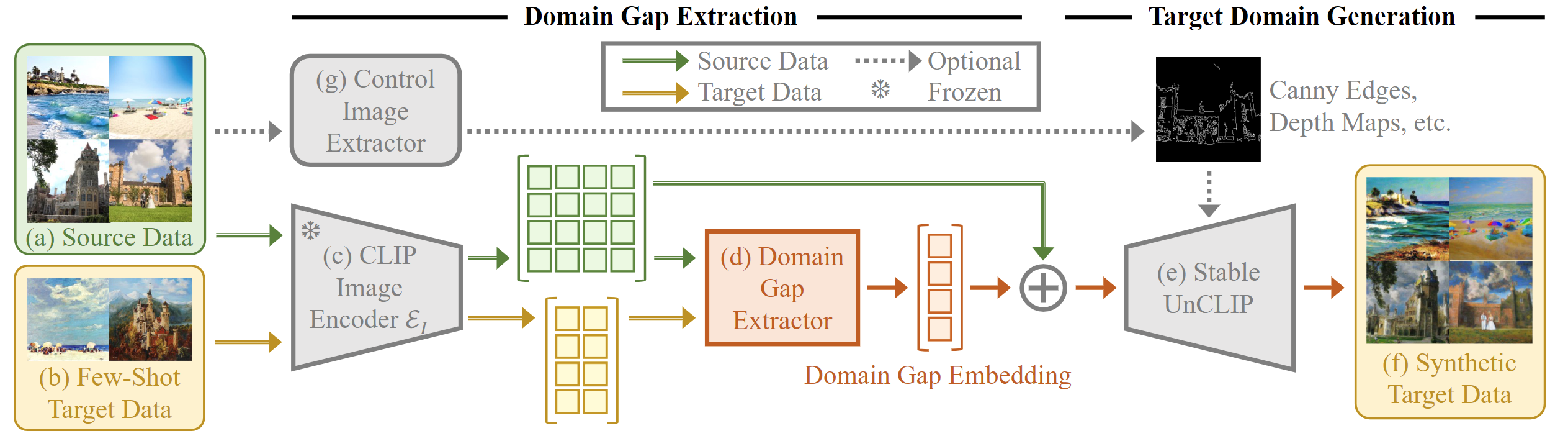
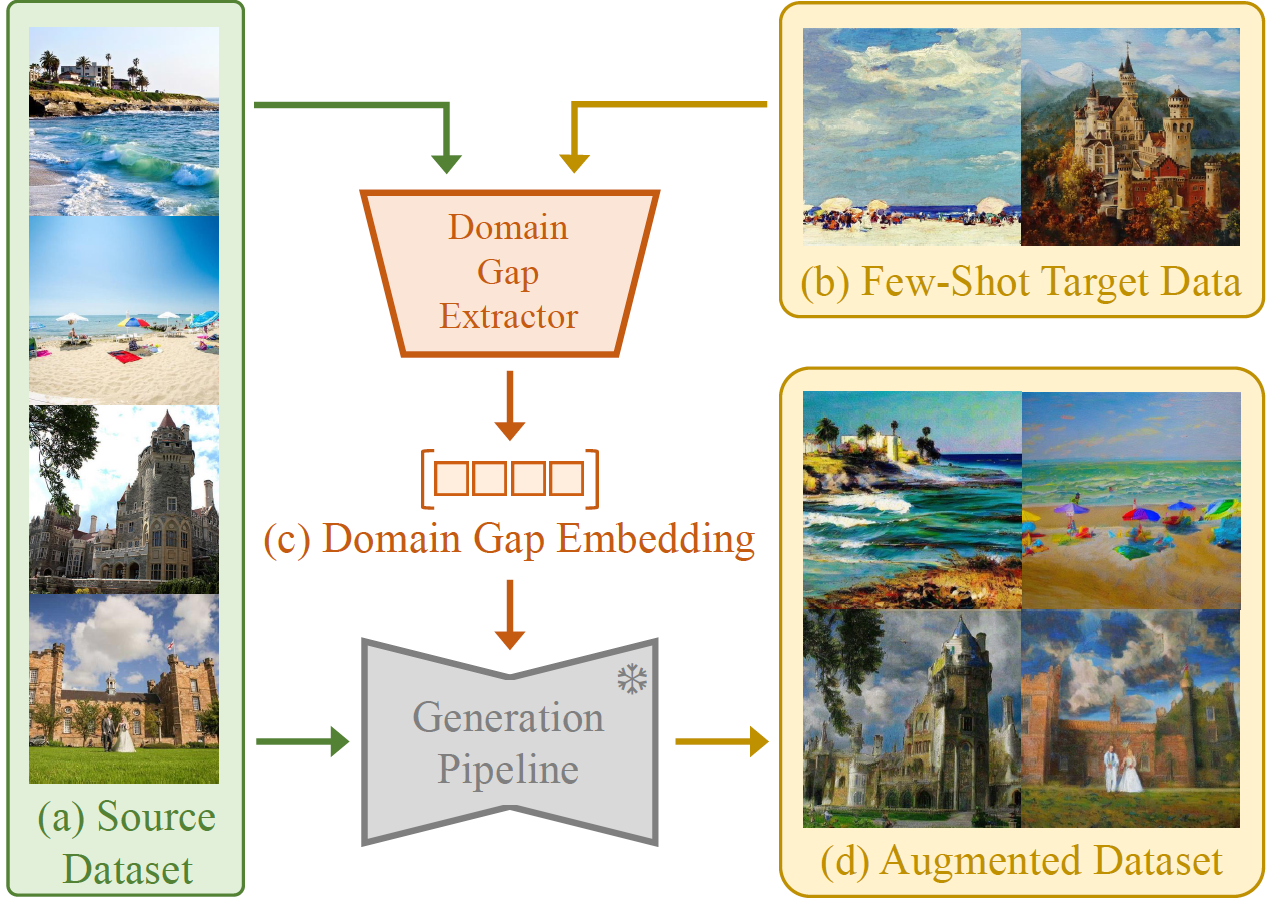
Above shows our proposed framework of Domain Gap Embeddings for Generative Dataset Augmentation.
The left part illustrates the process of Domain Gap Extraction:
The right part indicates the step of Target Domain Generation:
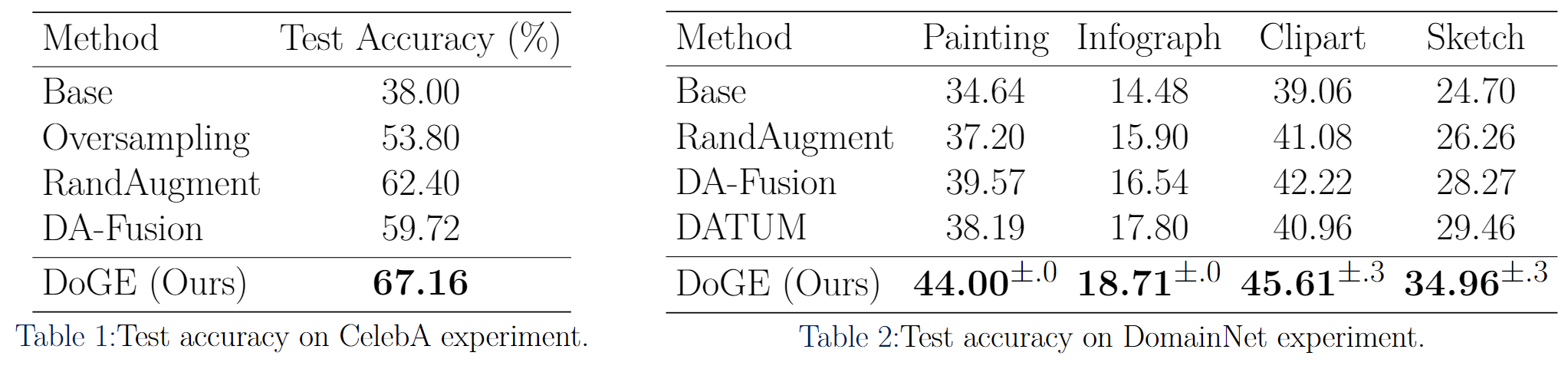
To illustrate the versatility and efficacy of DoGE, we evaluate performance improvements in various experiments including semantic augmentation on faces and style transfer on objects.

Above shows the effectiveness in semantic augmentation.
We use a subset of CelebA dataset with perceived males wearing eyeglasses and vice versa.
We select as few as 20 images in the target data distribution and
successfully add/remove eyeglasses from the faces.
Below illustrates our success in transferring styles. We use the real domain in the DomainNet dataset and successfully converted the realistic pictures of objects into four other styles.

@inproceedings{doge2024,
author={Yinong Oliver Wang, Younjoon Chung, Chen Henry Wu and Fernando De la Torre},
title={Domain Gap Embeddings for Generative Dataset Augmentation},
booktitle={CVPR},
year={2024},
}